
The Angular change detection mechanism is much more transparent and easier to reason about than its equivalent in AngularJs. But there are still situations (like when doing performance optimizations) when we really need to know what's going on under the hood. So let's dig deeper into change detection by going over the following topics:
- How is change detection implemented?
- What does an Angular change detector look like, can I see it?
- How does the default change detection mechanism work
- turning on/off change detection, and triggering it manually
- Avoiding change detection loops: Production vs Development mode
- What does the
OnPushchange detection mode actually do? - Using Immutable.js to simplify the building of Angular apps
- Summary
If you are looking for more information about OnPush change detection, have a look at the post Angular OnPush Change Detection and Component Design - Avoid Common Pitfalls.
How is change detection implemented?
Angular can detect when component data changes, and then automatically re-render the view to reflect that change. But how can it do so after such a low-level event like the click of a button, that can happen anywhere on the page?
To understand how this works, we need to start by realizing that in Javascript the whole runtime is overridable by design. We can override functions in String or Number if we so want.
Overriding browser default mechanisms
What happens is that Angular at startup time will patch several low-level browser APIs, such as for example addEventListener, which is the browser function used to register all browser events, including click handlers. Angular will replace addEventListener with a new version that does the equivalent of this:
The new version of addEventListener adds more functionality to any event handler: not only the registered callback is called, but Angular is given a chance to run change detection and update the UI.
How does this low-level runtime patching work?
This low-level patching of browser APIs is done by a library shipped with Angular called Zone.js. It's important to have an idea of what a zone is.
A zone is nothing more than an execution context that survives multiple Javascript VM execution turns. It's a generic mechanism which we can use to add extra functionality to the browser. Angular uses Zones internally to trigger change detection, but another possible use would be to do application profiling, or keeping track of long stack traces that run across multiple VM turns.
Browser Async APIs supported
The following frequently used browser mechanisms are patched to support change detection:
- all browser events (click, mouseover, keyup, etc.)
setTimeout()andsetInterval()- Ajax HTTP requests
In fact, many other browser APIs are patched by Zone.js to transparently trigger Angular change detection, such as for example Websockets. Have a look at the Zone.js test specifications to see what is currently supported.
One limitation of this mechanism is that if by some reason an asynchronous browser API is not supported by Zone.js, then change detection will not be triggered. This is, for example, the case of IndexedDB callbacks.
This explains how change detection gets triggered, but once triggered how does it actually work?
The change detection tree
Each Angular component has an associated change detector, which is created at application startup time. For example, take the following
TodoItem component:
This component will receive a Todo object as input and emit an event if the todo status is toggled. To make the example more interesting, the Todo class contains a nested object:
We can see that Todo has a property owner which is itself an object with two properties: first name and last name.
What does the Todo Item change detector look like?
We can actually see at runtime what the change detector looks like! To see it lets just add some code in the Todo class to trigger a breakpoint when a certain property is accessed.
When the breakpoint hits, we can walk through the stack trace and see change detection in action:
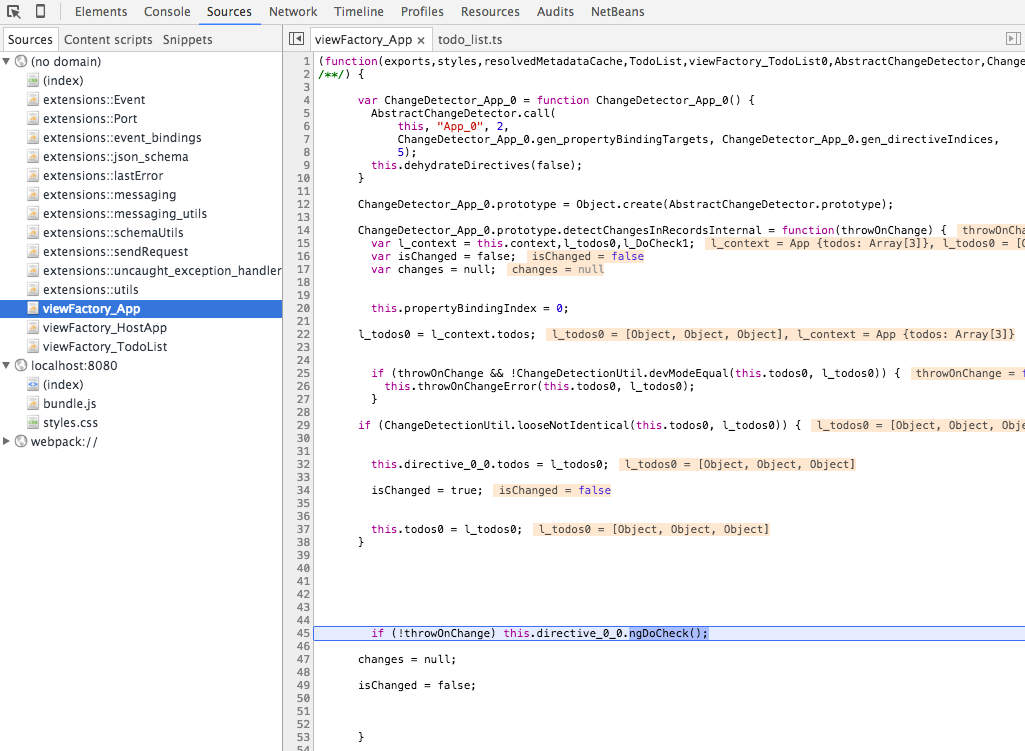
Don't worry, you will never have to debug this code! There is no magic involved either, it's just a plain Javascript method built at application startup time. But what does it do?
How does the default change detection mechanism work?
This method might look strange at first, with all the strangely named variables. But by digging deeper into it, we notice that it's doing something very simple: for each expression used in the template, it's comparing the current value of the property used in the expression with the previous value of that property.
If the property value before and after is different, it will set isChanged to true, and that's it! Well almost, it's comparing values by using a method called
looseNotIdentical(), which is really just a === comparison with special logic for the NaN case (see here).
And what about the nested object owner?
We can see in the change detector code that also the properties of the
owner nested object are being checked for differences. But only the firstname property is being compared, not the lastname property.
This is because lastname is not used in the component template ! Also, the top-level id property of Todo is not compared by the same reason.
With this, we can safely say that:
By default, Angular Change Detection works by checking if the value of template expressions have changed. This is done for all components.
We can also conclude that:
By default, Angular does not do deep object comparison to detect changes, it only takes into account properties used by the template
Why does change detection work like this by default?
One of the main goals of Angular is to be more transparent and easy to use, so that framework users don't have to go through great lengths to debug the framework and be aware of internal mechanisms in order to be able to use it effectively.
If you are familiar with AngularJs, think about $digest() and $apply() and all the pitfalls of when to use them / not to use them. One of the main goals of Angular is to avoid that.
What about comparison by reference?
The fact of the matter is that Javascript objects are mutable, and Angular wants to give full support out of the box for those.
Imagine what it would be if the Angular default change detection mechanism would be based on reference comparison of component inputs instead of the default mechanism? Even something as simple as a TODO application would be tricky to build: developers would have to be very careful to create a new Todo instead of simply updating properties.
But as we will see, it's still possible to customize Angular change detection if we really need to.
What about performance?
Notice how the change detector for the todo list component makes explicit reference to the todos property.
Another way to do this would be to loop dynamically through the properties of the component, making the code generic instead of specific to the component. This way we wouldn't have to build a change detector per component at startup time in the first place! So what's the story here?
A quick look inside the virtual machine
This all has to do with the way the Javascript virtual machine works. The code for dynamically comparing properties, although generic cannot easily be optimized away into native code by the VM just-in-time compiler.
This is unlike the specific code of the change detector, which does explicitly access each of the component input properties. This code is very much like the code we would write ourselves by hand, and is very easy to be transformed into native code by the virtual machine.
The end result of using generated but explicit detectors is a change detection mechanism that is very fast (more so than AngularJs), predictable and simple to reason about.
But if we run into a performance corner case, is there a way to optimize change detection?
The OnPush change detection mode
If our Todo list got really big, we could configure the TodoList component to update itself only when the Todo list changes. This can be done by updating the component change detection strategy to OnPush:
Let's now add to out application a couple of buttons: one to toggle the first item of the list by mutating it directly, and another that adds a Todo to the whole list. The code looks like this:
Lets now see how the two new buttons behave:
- the first button "Toggle First Item" does not work! This is because the
toggleFirst()method directly mutates an element of the list.
TodoListcannot detect this, as its input referencetodosdid not change - the second button does work! notice that the method
addTodo()creates a copy of the todo list, and then adds an item to the copy and finally replaces the todos member variable with the copied list. This triggers change detection because the component detects a reference change in its input: it received a new list! - In the second button, mutating directly the todos list will not work! we really need a new list.
Is OnPush really just comparing inputs by reference?
This is not the case, if you try to toggle a todo by clicking on it, it still works! Even if you switch TodoItem to OnPush as well. This is because
OnPush does not check only for changes in the component inputs: if a component emits an event that will also trigger change detection.
According to this quote from Victor Savkin in his blog:
When using OnPush detectors, then the framework will check an OnPush component when any of its input properties changes, when it fires an event, or when an Observable fires an event
Although allowing for better performance, the use of OnPush comes at a high complexity cost if used with mutable objects. It might introduce bugs that are hard to reason about and reproduce. But there is a way to make the use of OnPush viable.
Using Immutable.js to simplify the building of Angular apps
If we build our application using immutable objects and immutable lists only, its possible to use OnPush everywhere transparently, without the risk of stumbling into change detection bugs. This is because with immutable objects the only way to modify data is to create a new immutable object and replace the previous object. With an immutable object, we have the guarantee that:
- a new immutable object will always trigger
OnPushchange detection - we cannot accidentally create a bug by forgetting to create a new copy of an object because the only way to modify data is to create new objects
A good choice for going immutable is to use the Immutable.js library. This library provides immutable primitives for building applications, like for example immutable objects (Maps) and immutable lists.
This library can be also be used in a type-safe way, check this previous post for an example on how to do it.
Avoiding change detection loops: Production vs Development mode
One of the important properties of Angular change detection is that unlike AngularJs it enforces a uni-directional data flow: when the data on our controller classes gets updated, change detection runs and updates the view.
But that updating of the view does not itself trigger further changes which on their turn trigger further updates to the view, creating what in AngularJs was called a digest cycle.
How to trigger a change detection loop in Angular?
One way is if we are using lifecycle callbacks. For example in the TodoList component we can trigger a callback to another component that changes one of the bindings:
An error message will show up in the console:
EXCEPTION: Expression '{{message}} in App@3:20' has changed after it was checked
This error message is only thrown if we are running Angular in development mode. What happens if we enable production mode?
In production mode, the error would not be thrown and the issue would remain undetected.
Are change detection issues frequent?
We really have to go out of our way to trigger a change detection loop, but just in case its better to always use development mode during the development phase, as that will avoid the problem.
This guarantee comes at the expense of Angular always running change detection twice, the second time for detecting this type of cases. In production mode change detection is only run once.
turning on/off change detection, and triggering it manually
There could be special occasions where we do want to turn off change detection. Imagine a situation where a lot of data arrives from the backend via a websocket. We might want to update a certain part of the UI only once every 5 seconds. To do so, we start by injecting the change detector into the component:
As we can see, we just detach the change detector, which effectively turns off change detection. Then we simply trigger it manually every 5 seconds by calling detectChanges().
Let's now quickly summarize everything that we need to know about Angular change detection: what is it, how does it work and what are the main types of change detection available.
Summary
Angular change detection is a built-in framework feature that ensures the automatic synchronization between the data of a component and its HTML template view.
Change detection works by detecting common browser events like mouse clicks, HTTP requests, and other types of events, and deciding if the view of each component needs to be updated or not.
There are two types of change detection:
- default change detection: Angular decides if the view needs to be updated by comparing all the template expression values before and after the occurrence of an event, for all components of the component tree
- OnPush change detection: this works by detecting if some new data has been explicitly pushed into the component, either via a component input or an Observable subscribed to using the async pipe
The Angular default change detection mechanism is actually quite similar to AngularJs: it compares the values of templates expressions before and after a browser event to see if something changed. It does so for all components. But there are also some important differences:
For one there are no change detection loops, or a digest cycle as it was named in AngularJs. This allows to reason about each component just by looking at its template and its controller.
Another difference is that the mechanism of detecting changes in a component is much faster due to the way change detectors are built.
Finally and unlike in AngularJs, the change detection mechanism is customizable.
Do we really need to know that much about change detection?
Probably for 95% of applications and use cases it's safe to say that Angular Change Detection just works and there is not much that we need to know about it. Still it's useful to have an idea on how it works, for several reasons:
- for one it helps us understand some development error messages that we might come across like the one concerning change detection loops
- it helps us to read error stack traces, all those
zone.afterTurnDone()all of a sudden look a lot more clear - in cases where performance is at a premium (and are we sure we shouldn't just add pagination to that huge data table?), knowing about change detection helps us do performance optimizations.
If you would like to know about more advanced Angular Core features like change detection, we recommend checking the Angular Core Deep Dive course, where change detection is covered in much more detail.
If you enjoyed this article, we invite you to subscribe to the Angular University Newsletter:
If you are just getting started learning Angular, have a look at the Angular for Beginners Course:

Other posts on Angular
If you enjoyed this post, here some other popular posts on our blog:
- Angular Router - How To Build a Navigation Menu with Bootstrap 4 and Nested Routes
- Angular Router - Extended Guided Tour, Avoid Common Pitfalls
- Angular Components - The Fundamentals
- How to run Angular in Production Today
- How to build Angular apps using Observable Data Services - Pitfalls to avoid
- Introduction to Angular Forms - Template Driven, Model Driven or In-Between
- Angular ngFor - Learn all Features including trackBy, why is it not only for Arrays?
- Angular Universal In Practice - How to build SEO Friendly Single Page Apps with Angular